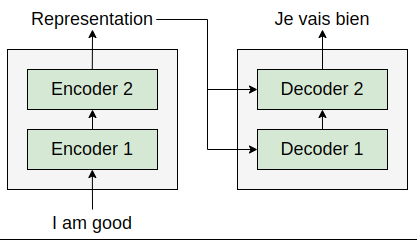
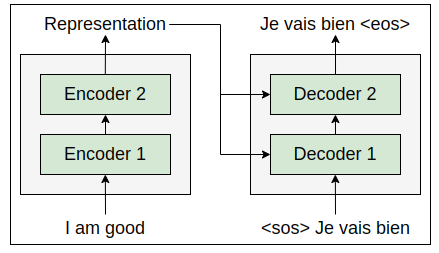
Suppose we want to translate the English sentence (source sentence) ‘I am good’ to the French sentence (target sentence) ‘Je vais bien’. To perform this translation, we feed the source sentence ‘I am good’ to the encoder. The encoder learns the representation of the source sentence. We’ve learned how exactly the encoder learns the representation of the source sentence. Now, we take this encoder’s representation and feed it to the decoder. The decoder takes the encoder representation as input and generates the target sentence ‘Je vais bien’, as shown in the following figure:

We learned earlier that instead of having one encoder, we can have a stack of N encoders. Similar to the encoder, we can also have a stack of N decoders. For simplicity, let’s set N=2. As shown in the following figure, the output of one decoder is sent as the input to the decoder above it. We can also observe that the encoder’s representation of the input sentence (encoder’s output) is sent to all the decoders. Thus, a decoder receives two inputs: one is from the previous decoder, and the other is the encoder’s representation (encoder’s output):
How the decoder generates the target sentence
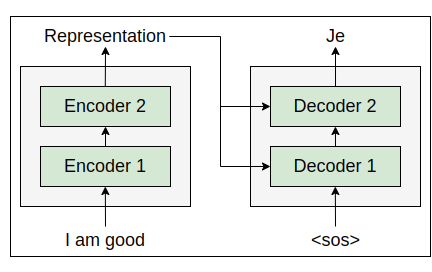
Okay, but how exactly does the decoder generate the target sentence? Let’s explore that in more detail. At time step the input to the decoder will be , which indicates the start of the sentence. The deocder takes as input and generates the first word in the target sentence, which is ‘Je’ as shown in the following figure
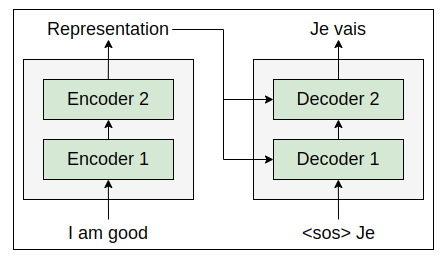
At time along with the current input, the decoder takes the newly generated word from the previous time step, and tries to generate the next word in the sentence. Thus, the decoder takes and ‘Je’ (from the previous step) as input and tries to generate the next word in the target sentence, as shown in the following figure.
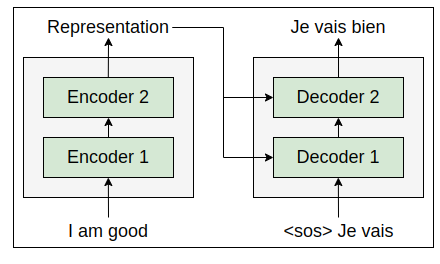
At time step =3, along with the current input, the decoder takes the newly generated word from the previous time step, t−1 , and tries to generate the next word in the sentence. Thus, the decoder takes ‘Je’, and ‘vais’ (from the previous step) as input and tries to generate the next word in the sentence, as shown in the following figure:
 Similarly, the decoder combines the newly generated word with the input on every time step and predicts the next word. Thus, at time step t=4 the decoder takes ‘Je’, ‘vais’, and ‘bien’ as input and tries to generate the next word in the sentence, as shown in the following figure:
Similarly, the decoder combines the newly generated word with the input on every time step and predicts the next word. Thus, at time step t=4 the decoder takes ‘Je’, ‘vais’, and ‘bien’ as input and tries to generate the next word in the sentence, as shown in the following figure:
 As we can observe from the preceding figure, once the token, which indicates the end of sentence, is generated, it implies that the decoder has completed generating the target sentence.
As we can observe from the preceding figure, once the token, which indicates the end of sentence, is generated, it implies that the decoder has completed generating the target sentence.
Decoder Architecture with positional encoding
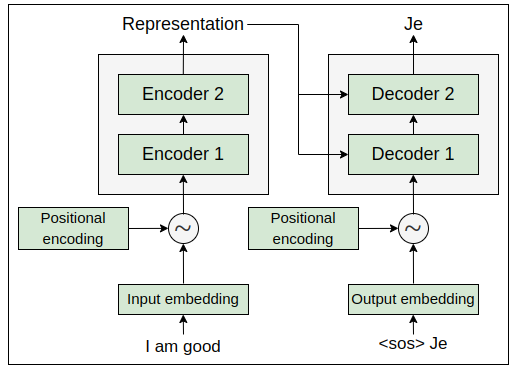
In the encoder section, we learned that we convert the input into an embedding matrix and add the positional encoding to it, and then feed it as input to the encoder. Similarly, here, instead of feeding the input directly to the decoder, we convert it into an embedding, add the positional encoding to it, and then feed it to the decoder.
For example, as shown in the following figure, say at time step t=2, we convert the input into an embedding (we call it an output embedding because here we are computing the embedding of the words generated by the decoder in previous time steps), add the positional encoding to it, and then send it to the decoder:
Components of the decoder
Okay, but the ultimate question is how exactly does the decoder work? What’s going on inside the decoder? Let’s explore this in detail. A single decoder block with all of its components is shown in the following figure
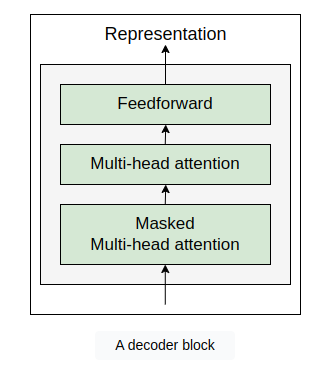
From the preceding figure, we can observe that the decoder block is similar to the encoder and here we have three sublayers:
-
Masked multi-head attention
-
Multi-head attention
-
Feedforward network
Similar to the encoder block, here we have multi-head attention and feedforward network sublayers. However, here we have two multi-head attention sublayers and one of them is masked.
Masked Multi-Head Attention
In our English-to-French translation task, say our training dataset looks like the one shown here:
A sample training set
| Source sentence | Target sentence |
| I am good | Je vais bien |
| Good morning | Bonjour |
| Thank you very much | Merci beaucoup |
| By looking at the preceding dataset, we can understand that we have source and target sentences. We saw how the decoder predicts the target sentence word by word in each time step and that happens only during testing. |
During training, since we have the right target sentence, we can just feed the whole target sentence as input to the decoder but with a small modification. We learned that the decoder takes the input as the first token, and combines the next predicted word to the input on every time step for predicting the target sentence until the token is reached. So, we can just add the token to the beginning of our target sentence and send that as an input to the decoder.
Say we are converting the English sentence ‘I am good’ to the French sentence ‘Je vais bien’. We can just add the token to the beginning of the target sentence and send Je vais bien as an input to the decoder, and then the decoder predicts the output as Je vais bien as shown in the following figure:
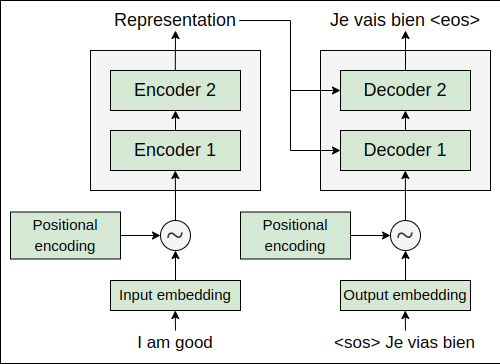
But how does this work? Isn’t this kind of ambiguous? Why do we need to feed the entire target sentence and let the decoder predict the shifted target sentence as output? Let’s explore this in more detail.
We learned that instead of feeding the input directly to the decoder, we convert it into an embedding (output embedding matrix) and add positional encoding, and then feed it to the decoder. Let’s suppose the following matrix, X, is obtained as a result of adding the output embedding matrix and positional encoding:
